Our research
Our lab develops statistical and computational methods to understand how genetic perturbations affect molecular and cellular phenotypes. By combining experimental perturbation technologies and observational human genetics with modern statistical inference, we aim to identify the mechanisms through which genetic variation influences disease. We focus on high-throughput perturbation assays including deep mutational scanning, CRISPR screens, cell villages, and Perturb-seq, to build quantitative models of gene function and causal biological pathways.
Statistical foundations for perturbation assays
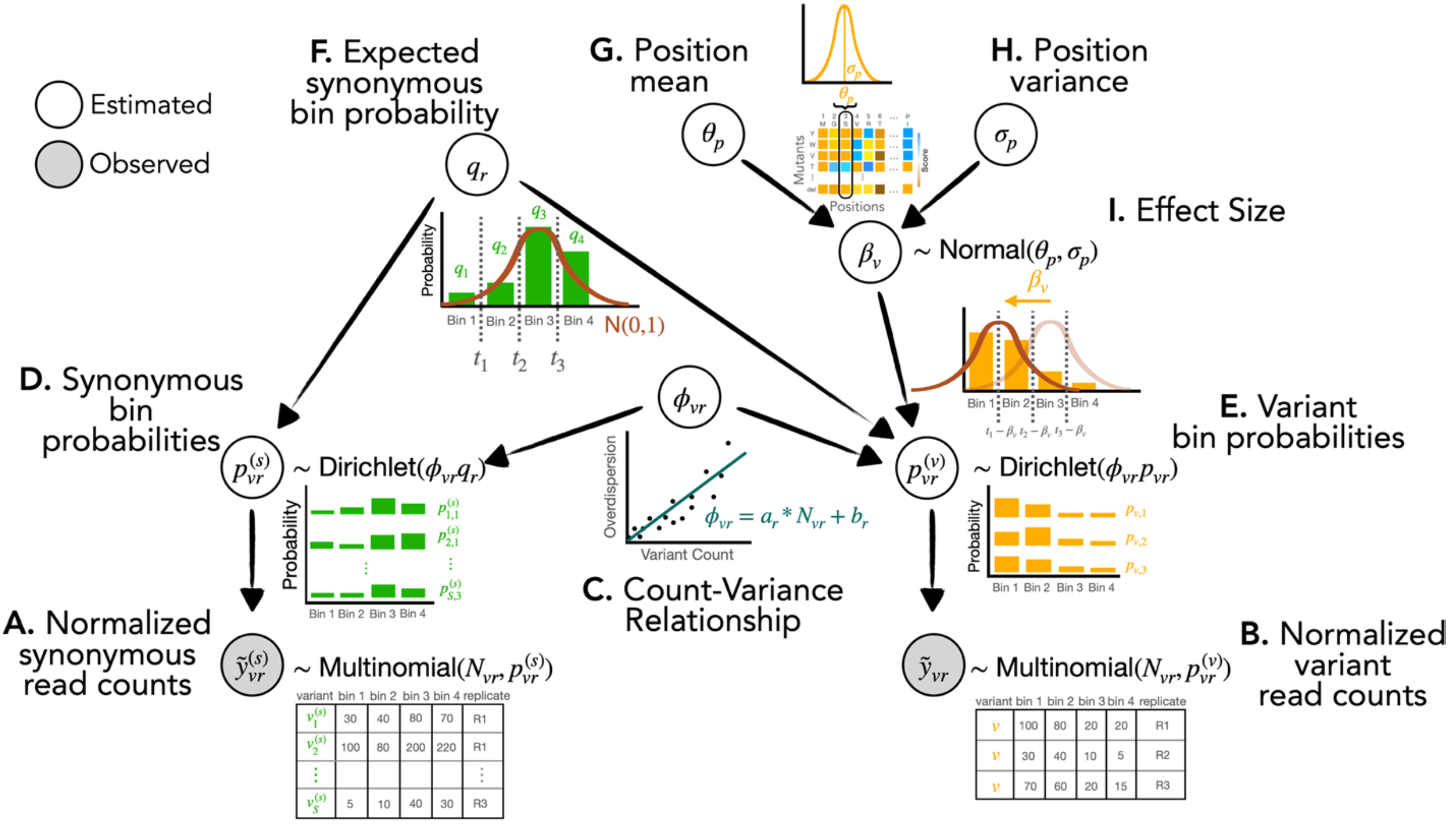
We have developed a number of tools to analyze Deep Mutational Scans (both fitness and FACS-based), Massively Parallel Reporter Assays, and Perturb-seq. These methods are generally geared towards estimating effect sizes in small-sample experiments which are common (i.e. three replicates).
In vitro human genetics
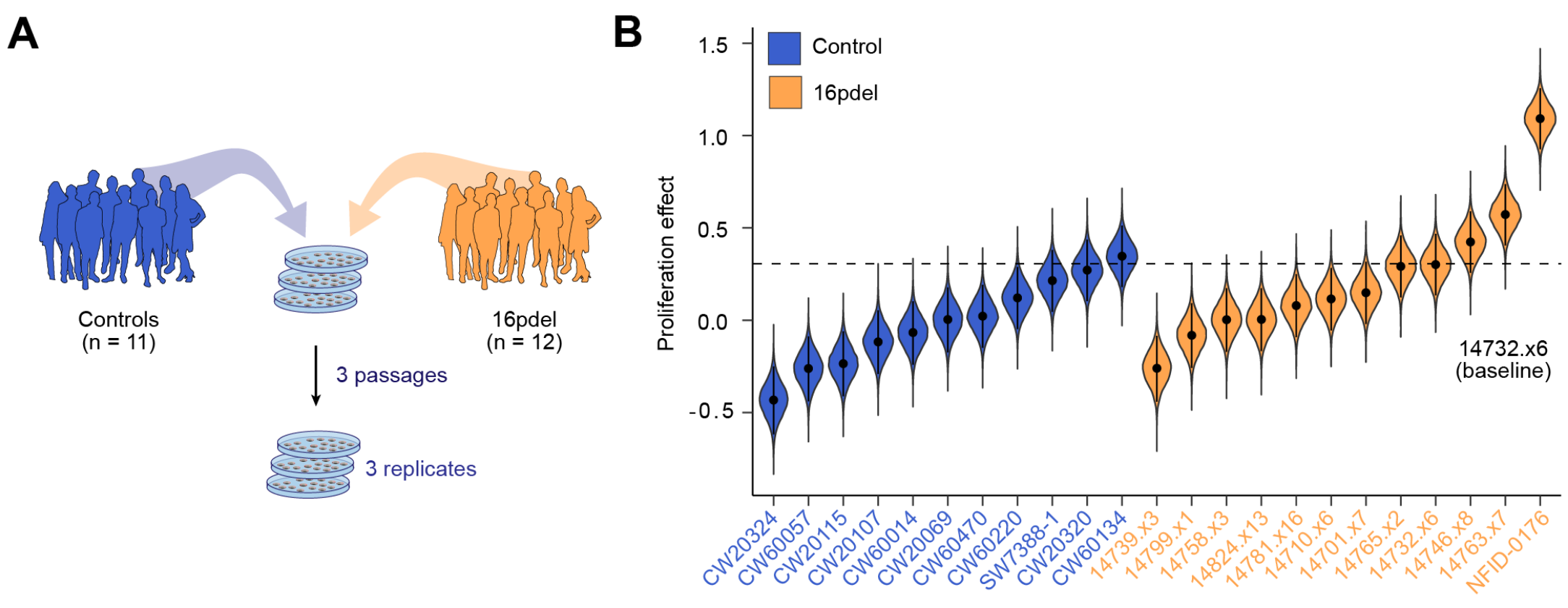
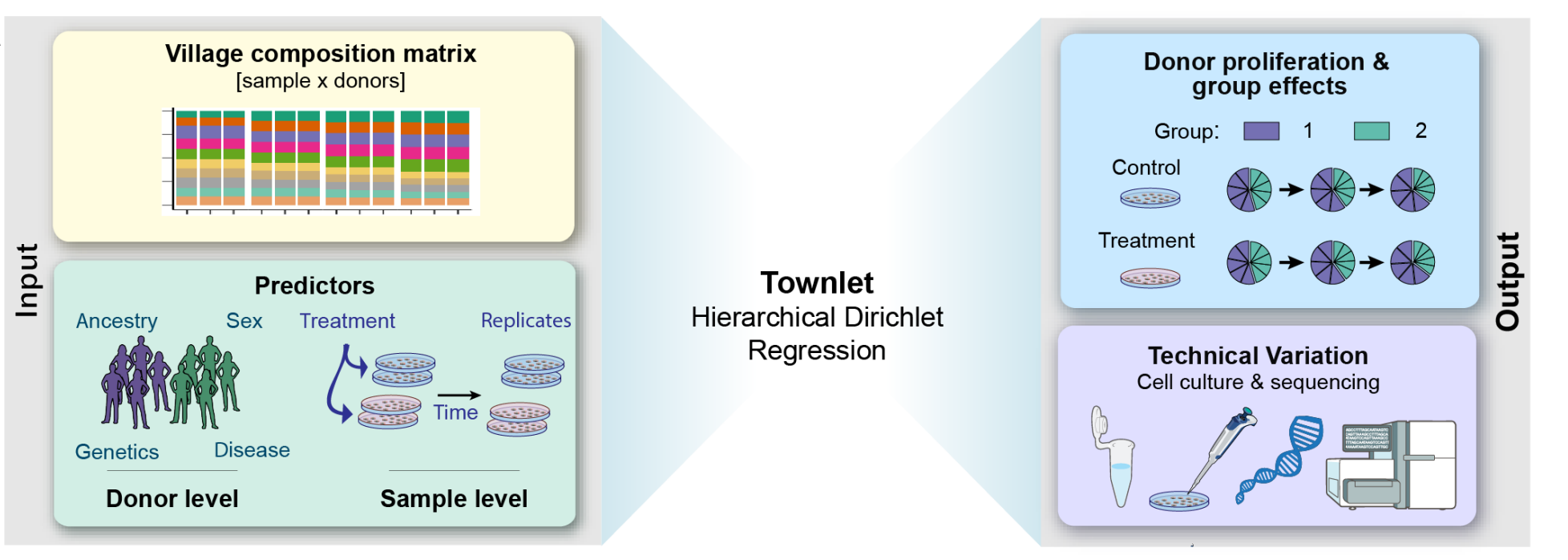
Cell Villages provide an experimental framework for studying human genetic variation in controlled cellular environments. By co-culturing cells from many donors, these systems enable scalable studies of molecular and complex traits while preserving naturally occurring human variation. Our lab develops statistical methods, experimental design strategies, and pharmacogenomic analyses for Cell Village experiments, enabling population-scale genetics in vitro. Thus far, we have developed Townlet to analyze Census-seq Cell Villages. We are currently developing experimental design techniques as well as methods for pharmacogenomic analysis of Cell Villages.
From perturbation to phenotype
Every tool we have developed serves a purpose in a collaboration. We use perturbation experiments and natural genetic variation to answer biological questions ranging from pharmacogenomics and protein function to gene-gene and gene-environment interactions. Currently, we are working on pharmacogenomics in DMS, gene-gene interactions and their affects on protein function, gene-by-environment interactions with neural development.